一个朋友在群里问为什么在 analyzer 里看到的和从索引里面查出来的不一样,在过滤器里面配置了:
1 | <charFilter class="solr.HTMLStripCharFilterFactory"/> |
并且在 analyzer 里面调试确实去除了 HTML,但是在查询索引的时候 HTML 又出来了。
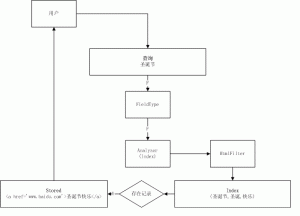
刚接触的同学可能对于 Solr/Lucene 的数据存储不是特别清楚,简单的说,Solr 数据分两部分:存储和索引
索引过程
数据提交到 Solr 后,按照配置进行索引和存储两部分处理,存储带 HTML,索引不带 HTML(因为 filter 可以过滤索引数据,不能过滤存储数据)
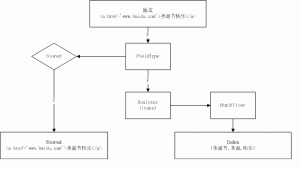
查询过程
查询请求提交到 Solr 后先经过 analyzer 处理,然后到索引里面查询数据,如果找到记录从存储返回原文